Current issue
Archive
Manuscripts accepted
About the Journal
Editorial office
Editorial board
Section Editors
Abstracting and indexing
Subscription
Contact
Ethical standards and procedures
Most read articles
Instructions for authors
Article Processing Charge (APC)
Regulations of paying article processing charge (APC)
NEPHROLOGY / RESEARCH PAPER
Comparison of ChatGPT and Claude in Managing Real-Life Difficult Nephrology Cases
1
İstanbul University-Cerrahpasa, Cerrahpasa Medical Faculty, Department of Nephrology, Turkey
2
Doktor Lutfi Kirdar City Hospital, Department of Nephrology, Turkey
3
Sinop University, Faculty of Science and Letters, Department of Data Science and Analytics, Turkey
Submission date: 2025-11-18
Final revision date: 2025-12-26
Acceptance date: 2026-01-29
Online publication date: 2026-05-01
Corresponding author
Nurhan Seyahi
İstanbul University-Cerrahpasa, Cerrahpasa Medical Faculty, Department of Nephrology, Turkey
İstanbul University-Cerrahpasa, Cerrahpasa Medical Faculty, Department of Nephrology, Turkey
KEYWORDS
TOPICS
ABSTRACT
Introduction:
Artificial intelligence (AI) based large language models (LLMs) are promising tools for clinical decision support, but their reliability in specialized fields like nephrology is still uncertain. ChatGPT and Claude represent distinct AI architectures with potentially different clinical utilities. We aimed to compare the diagnostic accuracy, treatment recommendations, and overall clinical utility of these two AI models in managing real life difficult nephrology cases.
Material and methods:
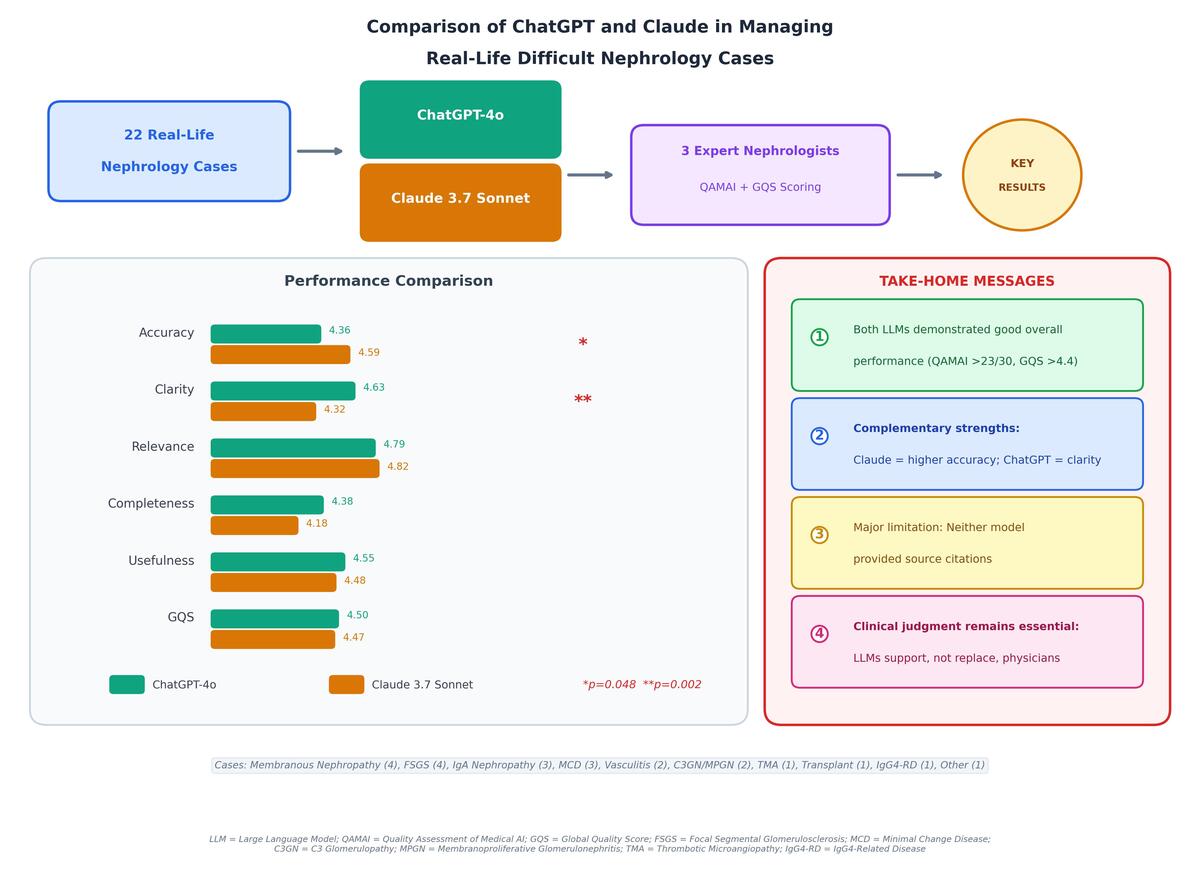
Twenty-two real nephrology cases from a tertiary care university hospital were presented to both models, covering disorders such as glomerulonephritis, acute kidney injury, vasculitis, and transplant complications. Each model’s output was assessed for diagnostic accuracy, risk evaluation, test recommendations, and treatment planning. Three independent nephrologists evaluated the responses using the Quality Assessment of Medical Information (QAMAI) and Global Quality Score (GQS) tools. Statistical comparisons were performed using the Wilcoxon signed-rank test, with p<0.05 considered significant.
Results:
Claude achieved higher diagnostic accuracy than ChatGPT (4.59 ± 0.41 vs. 4.36 ± 0.48; p=0.048), whereas ChatGPT scored better in clarity (4.63 ± 0.30 vs. 4.32 ± 0.29; p=0.002). No significant differences were found in relevance, completeness, usefulness, or source citation. Overall QAMAI scores were comparable between the two models (ChatGPT: 23.72 ± 1.46; Claude: 23.39 ± 1.43; p=0.371). Inter-rater reliability ranged from moderate to good, with the highest agreement observed for ChatGPT’s GQS.
Conclusions:
Both ChatGPT and Claude demonstrate notable potential as decision-support tools in nephrology. Claude provided slightly higher diagnostic accuracy, while ChatGPT offered greater clarity. Despite these promising results, clinical judgment remains essential when interpreting LLM-generated suggestions.
Artificial intelligence (AI) based large language models (LLMs) are promising tools for clinical decision support, but their reliability in specialized fields like nephrology is still uncertain. ChatGPT and Claude represent distinct AI architectures with potentially different clinical utilities. We aimed to compare the diagnostic accuracy, treatment recommendations, and overall clinical utility of these two AI models in managing real life difficult nephrology cases.
Material and methods:
Twenty-two real nephrology cases from a tertiary care university hospital were presented to both models, covering disorders such as glomerulonephritis, acute kidney injury, vasculitis, and transplant complications. Each model’s output was assessed for diagnostic accuracy, risk evaluation, test recommendations, and treatment planning. Three independent nephrologists evaluated the responses using the Quality Assessment of Medical Information (QAMAI) and Global Quality Score (GQS) tools. Statistical comparisons were performed using the Wilcoxon signed-rank test, with p<0.05 considered significant.
Results:
Claude achieved higher diagnostic accuracy than ChatGPT (4.59 ± 0.41 vs. 4.36 ± 0.48; p=0.048), whereas ChatGPT scored better in clarity (4.63 ± 0.30 vs. 4.32 ± 0.29; p=0.002). No significant differences were found in relevance, completeness, usefulness, or source citation. Overall QAMAI scores were comparable between the two models (ChatGPT: 23.72 ± 1.46; Claude: 23.39 ± 1.43; p=0.371). Inter-rater reliability ranged from moderate to good, with the highest agreement observed for ChatGPT’s GQS.
Conclusions:
Both ChatGPT and Claude demonstrate notable potential as decision-support tools in nephrology. Claude provided slightly higher diagnostic accuracy, while ChatGPT offered greater clarity. Despite these promising results, clinical judgment remains essential when interpreting LLM-generated suggestions.
| eISSN: | 1896-9151 |
| ISSN: | 1734-1922 |
We process personal data collected when visiting the website. The function of obtaining information about users and their behavior is carried out by voluntarily entered information in forms and saving cookies in end devices. Data, including cookies, are used to provide services, improve the user experience and to analyze the traffic in accordance with the Privacy policy. Data are also collected and processed by Google Analytics tool (more).
You can change cookies settings in your browser. Restricted use of cookies in the browser configuration may affect some functionalities of the website.
You can change cookies settings in your browser. Restricted use of cookies in the browser configuration may affect some functionalities of the website.