Introduction
The World Health Organization (WHO) declared the novel coronavirus (COVID-19) a worldwide pandemic on 11 March 2020 [1]. COVID-19 has forever changed the perception of the epidemiological threat from new pathogens. It has affected almost every area of our daily life and forced the modification of recommendations for the management of infectious patients. The main reason behind sudden and rapid accumulation of a large number of infected individuals in the early stages of consecutive waves of COVID-19 was the inability to expeditiously and effectively identify such a large number of suspected cases [2]. Limitations of the PCR test, which is the gold standard for COVID-19 detection, have challenged health systems around the world due to shortages of specialised equipment and trained operators, especially during exponential seasonal increases in infection rates. Factors that also need to be taken into account are the relatively low sensitivity of the test, and the extended waiting period for the test result [3]. In addition to the difficulties associated with laboratory testing, diagnostic problems arise from the fact that the symptoms of infection are not very specific [4, 5].
One of the dominant approaches to prevent the transmission of the pathogen was the isolation of all people suspected of being infected, which consequently led to the stalling of most branches of the economy and a deep worldwide economic crisis [6]. The world’s healthcare systems has been affected in a particularly dangerous way. It was caused not only by an excessive influx of patients, but also by extreme personnel shortages [7, 8]. The shortages were caused, among other things, by the quarantine imposed on workers who came into contact with SARS-CoV-2 infected persons without wearing specialised personal protective equipment, due to the impossibility of objective assessment of the real risk of their infection. Given the above, the search for a tool to estimate the risk of infection after contact with a person infected with COVID-19 while being aware of the circumstances of this contact (aware contact with infected individual – ACII), preferentially consuming a minimal amount of material and human resources, is an important step in preventing the development of the COVID-19 pandemic and its negative economic consequences. The effectiveness of such a tool would also set an invaluable precedent in the crises caused by any new future pathogens with the potential to cause epidemics or pandemics. Those are well known to occur periodically – in the case of epidemics, every few years; and in the case of global pandemics, every few decades [9].
The sought solution can be found in in silico research, which is a peculiar innovation in the medical field, when most of the aforementioned problems may be solved with the use of computer simulations. Simulations require the use of a model that is a synthetic and precise description of the studied phenomenon. There are possible situations in which the creation of a classical mathematical model in the form of a precise algorithm is difficult or impossible due to its complexity, or when the phenomenon is not known well enough – exactly as in the case of new epidemics such as COVID-19. The solution to this problem can be a so-called behavioural model, the premise of which is not to reproduce the internal relationships of all the components of the studied phenomenon, but to simulate its behaviour on the basis of its initial state. Artificial neural networks are capable of creating such models.
Artificial neural networks by their structure and operation imitate the operation of the human brain [10]. The most important element in the process of creating an efficiently functioning artificial neural network multilayer perceptron type, besides the selection of input variables and appropriate architecture, is a process called training with the teacher. The essence of this process is to present the network with a set of tasks with a known answer. The network, after attempting to solve the task on its own, compares its answer with the true result. Then, based on the obtained error value, the network appropriately changes the values of the so-called weight parameters in order to reduce this error [11]. A network that has successfully completed this kind of self-programming with a large enough database is then able to generalize the information it has, to examples of similar sets that it has not previously analysed. In other words, it is able to simulate the result of a similar system with different input values. Similar models have already been used as a tool for the early identification of COVID-19 pneumonia, or prediction of the number of new cases and the number of cured cases [12–14].
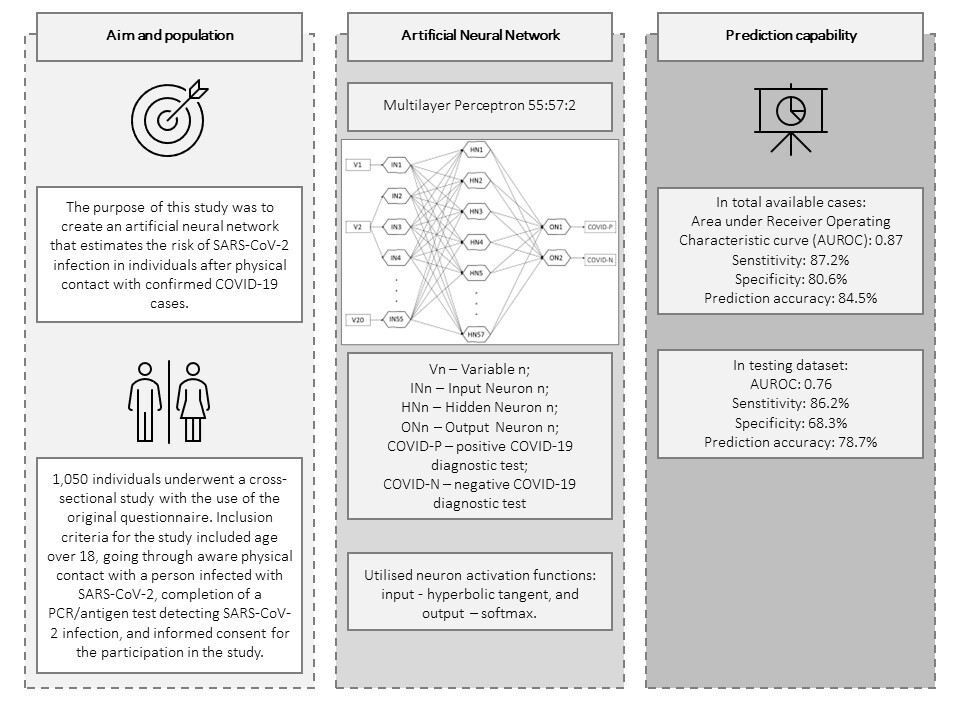
The main goal of this study is to create an artificial neural network to determine the risk of infection and symptomatic COVID-19 disease in individuals after physical contact with patients with confirmed SARS-CoV-2 infection.
Material and methods
Study design and population
It has been postulated that a tool operating on the basis of multivariate analyses should be based on the minimum number of cases corresponding to the square of the number of analysed variables for the tool to show satisfactory generalisation capabilities. The number of variables originally prepared for analyses at the stage of study design was 30; therefore the minimal number of utilised cases was estimated to be 900. Between June 2020 and August 2022, 1,050 individuals underwent a cross-sectional study using the original questionnaire. Inclusion criteria for the study included age over 18, having had ACII, completion of a PCR/antigen test detecting SARS-CoV-2 infection, and informed consent for participation in the study. Participants were required to take the survey either online or by completing a paper questionnaire. Given that some participants were members of the academic community of the Medical University of Lublin, which exposed the study to selection bias, additional participants were included in the analysis – patients of medical clinics unrelated to infectious diseases, and other individuals recruited through online advertising.
We present the following article in accordance with the STROBE v4 reporting checklist.
Questionnaire
The survey was conducted using an original questionnaire which included instructions and 118 questions concerning demographic issues, the result of a SARS-CoV-2 test, use of personal protective equipment, prophylactic behaviours, general health status including medical history, lifestyle, addictions, and sleep quality. A separate section on the specific circumstances of the ACII was also included. In addition, for those who become ill after the ACII, the questions were related to disease symptoms; however, data regarding symptoms were not included in this article. In the process of questionnaire development the questions were selected based on a literature review regarding factors affecting COVID-19 infection, and the opinion of an expert. The collected data were subjected to univariate statistical analysis and multivariate analysis using artificial neural networks. In order to reduce the risk of self-reporting bias, the questionnaire was solved anonymously. The items in the questionnaire were mostly mandatory closed questions, and did not address issues socially perceived as controversial.
Statistical analysis
The analyses were carried out using Statistica v13.3 software. The statistical significance of differences between the two quantitative variables was tested using the Mann-Whitney U test. For ordinal and nominal variables, Pearson’s χ2 test was used. Results were considered statistically significant when p ≤ 0.05. The only case of missing data occurred in variables concerning blood type, which was interpreted as an unknown blood type and was included in the analyses.
Artificial neural network
The collected data were analysed using an artificial neural network. The design of the artificial neural network was established in a 6-stage experimental process, which began with the generation of networks of all available types (multilayer perceptrons and radial basis function networks) and configurations of settings regarding the error function and activation functions offered by Statistica v13.3 software, in a random manner. The best networks of a given stage were selected on the basis of the following characteristics in the order listed – the highest prediction accuracy in the testing group, the largest area (AUROC) under the receiver operating characteristic (ROC) curve, and the lowest number of hidden neurons. 1000 cases (COVID-TOTAL) were included in the analyses. The learning, testing and validation groups were drawn randomly every time at a percentage of 70% (N = 700), 15% (N = 150) and 15% (N = 150) of all cases, respectively. 50 cases were used exclusively for internal tests of the Risk Calculator developed on the basis of the final network.
The initial stage of the artificial neural network design process showed the need to reduce the number of input variables – the database after the necessary transformations contained 83 variables, including quantitative, ordinal and nominal variables, which translated into 245 input neurons in stage 1, in which 5,000 networks were generated. In stages 2 and 3, in which a total of 2,000 networks were generated, the number of variables used to train the networks was significantly reduced, with the selection of discarded variables based on univariate analysis and expert opinion. Variables primarily related to participants’ lifestyles and the use of personal protective equipment outside the ACII were dropped. Stage 4 included 25 variables and involved the reduction of variables based on the negligible activation power of the neurons assigned to them. 10,000 networks with 59 input neurons were generated. Stage 5 involved converting the quantitative variables “height” and “weight” into an ordinal variable containing categories according to body mass index (BMI categories), and removing the variable “satisfaction with sleep quality”. 10,000 networks with 59 input neurons were generated. Prior to Stage 6, 3 additional, minor generation sessions (below 500 networks each) were conducted, the results of which were removal of the variables related to completion of mandatory vaccinations based on negligible activation power, and conversion of the variable “length of night sleep” from ordinal to quantitative. Stage 6, in which the final network was selected, included the input 20 variables listed in Table I. Based on the previous stages, it was determined that the following network architecture would be used: a multilayer perceptron, a cross entropy error function and neuron activation functions: input – hyperbolic tangent, and output – softmax. 15,000 networks with 55 input neurons were generated. The most optimal network according to the aforementioned criteria was a network with 57 neurons in the hidden layer, which went through 73 learning epochs with the Broyden-Fletcher-Goldfarb-Shanno algorithm and is shown in Figure 1.
Figure 1
Architecture of the final artificial neural network. Softmax activation function is a multivariable function, and therefore cannot be illustrated in a plot
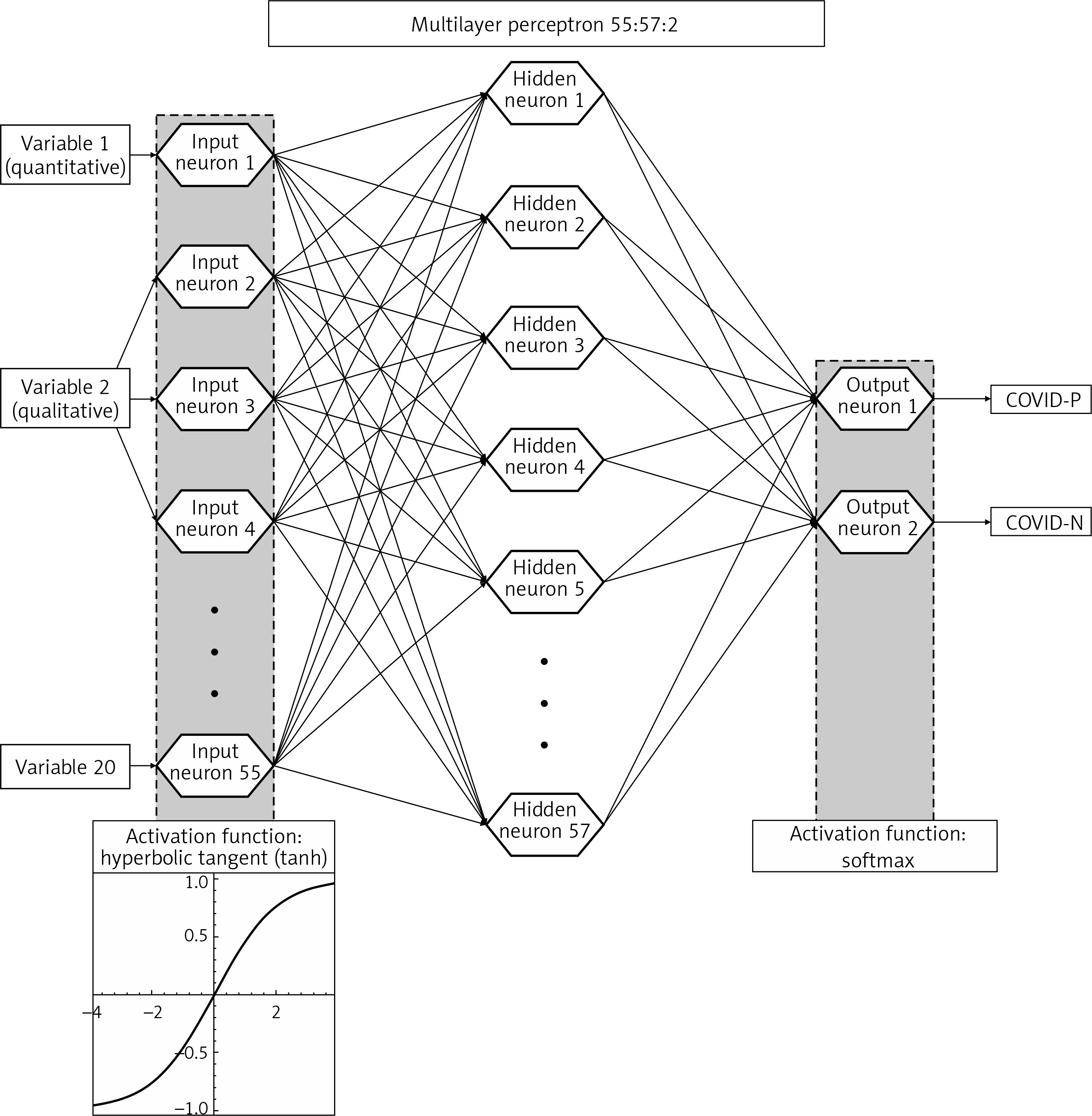
Table I
Variables used in step 6 of the artificial neural network analysis
Results
Univariate analysis
Of the 1,000 study participants, the group of participants whose SARS-CoV-2 infection detection test performed after the ACII was positive (COVID-P) included 587 (58.7%) participants and the negative group (COVID-N) included 413 (41.3%) participants. Tables II and III show the detailed demographic characteristics of the study participants, and the test of differences between the COVID-P and COVID-N groups.
Table II
Characteristics of qualitative variables analysed by the artificial neural network
Table III
Characteristics of quantitative variables analysed by the artificial neural network
Artificial neural network
The selected model showed satisfactory quality in both the learning and test groups and exceeded an AUROC of 0.75 in both the learning and test groups. In the learning group, the AUROC was 0.97 (Figure 2), and the accuracy of prediction expressed as the ratio of correctly predicted results to all results in the learning group was 90.3%. The sensitivity of the model in this group expressed by the fraction of the number of results classified correctly as positive (TP) to the number of all positive results was 92.4%. The specificity of the model expressed as the fraction of the number of results classified correctly as negative (TN) to the number of all negative results was 87.2%. In the test group, the AUROC was 0.76 (Figure 3), while the prediction accuracy was 78.7%. The sensitivity of the model in this group was 86.2%, while the specificity was 68.2%. The model in the analysis of COVID-TOTAL achieved an AUROC of 0.90, prediction accuracy of 84.5%, sensitivity of 87.2% and specificity of 80.6%. A summary of the model’s prediction quality is shown in Table IV.
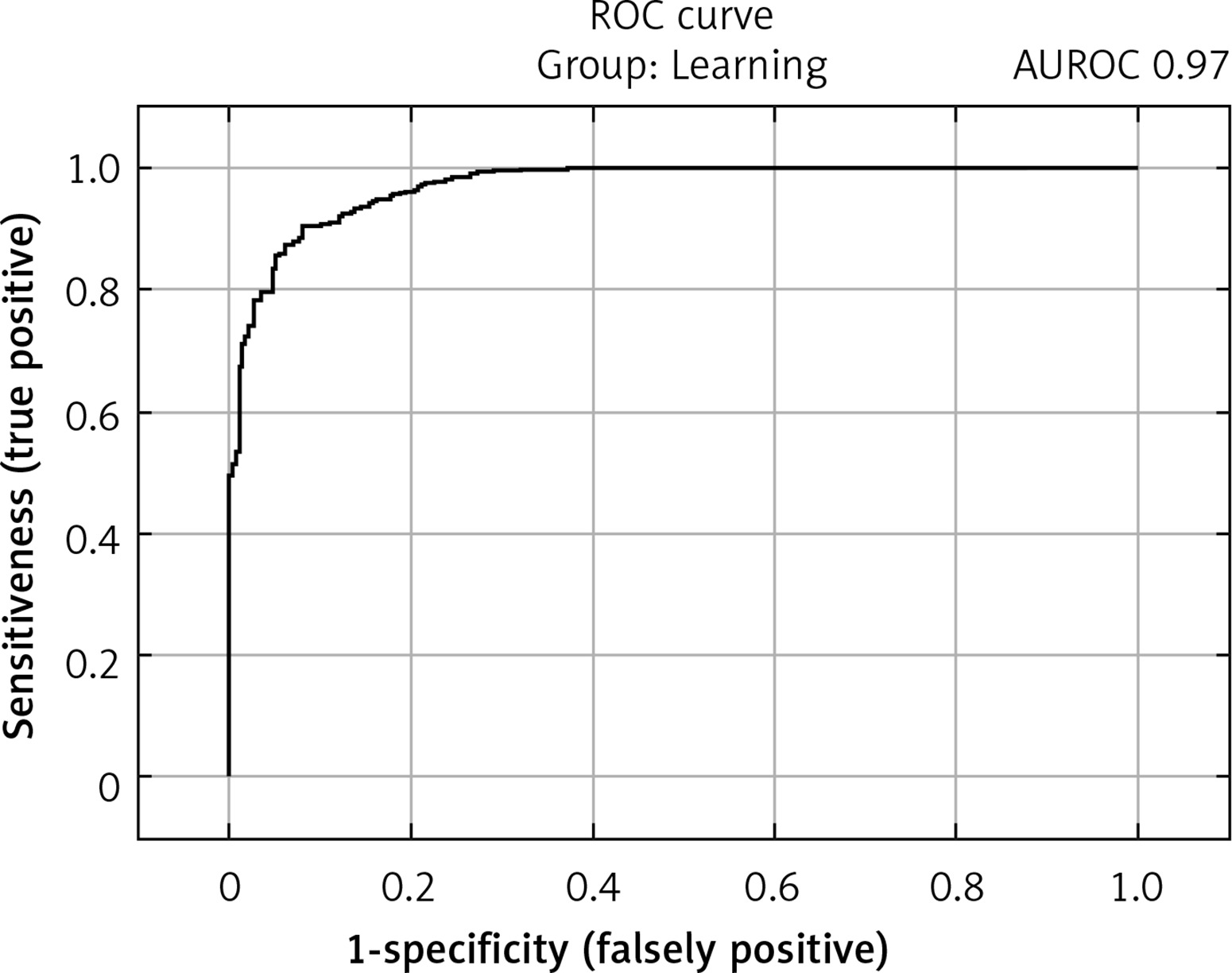
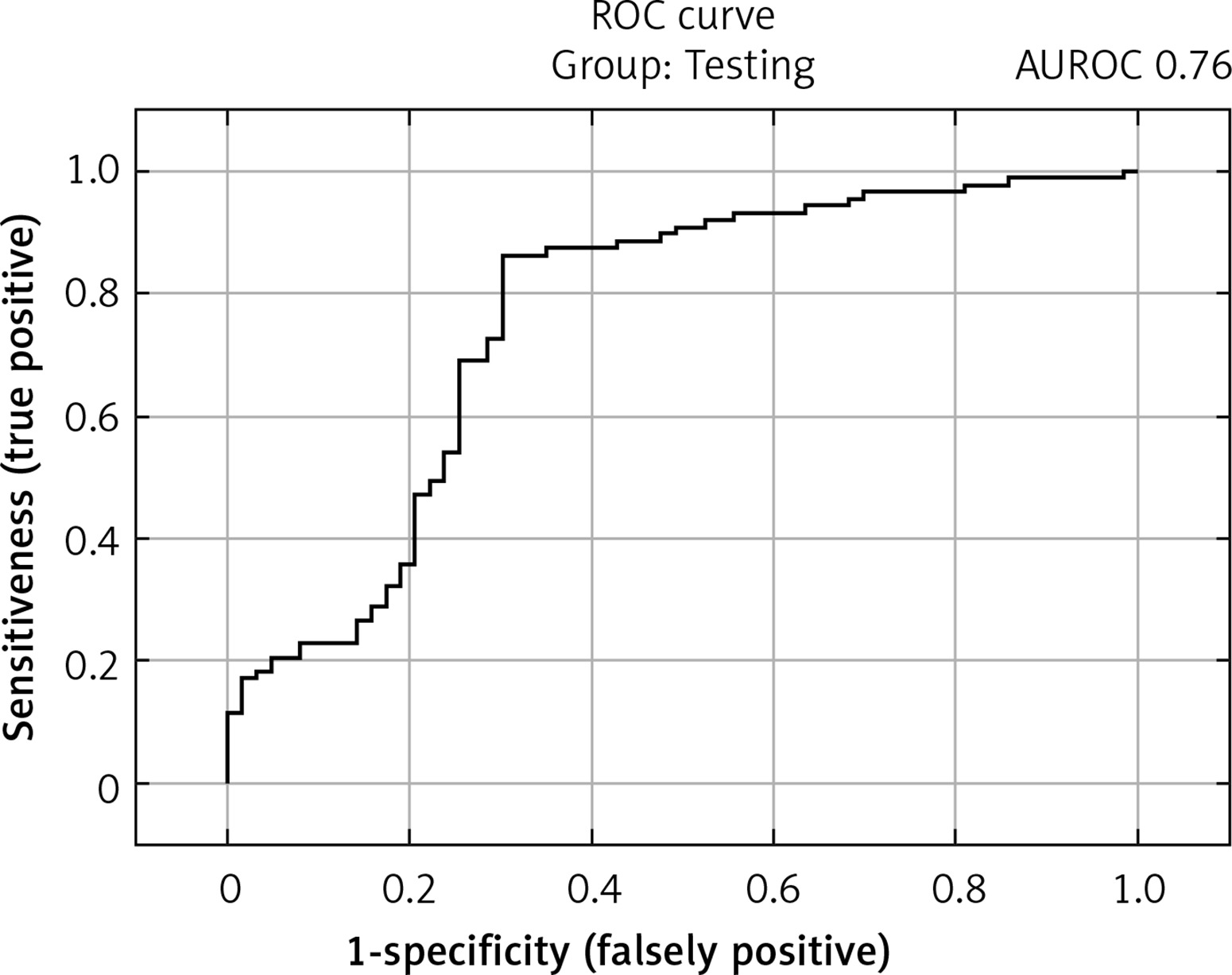
Table IV
Summary of the model prediction quality
| Parameter | COVID-P | COVID-N | COVID-Total |
|---|---|---|---|
| Total | 587 | 413 | 1000 |
| Correct | 512 | 333 | 845 |
| Incorrect | 75 | 80 | 155 |
| Correct (%) | 87.2 | 80.6 | 84.5 |
| Incorrect (%) | 12.8 | 19.4 | 15.5 |
The tool was exported and programmed in the form of a Risk Calculator and implemented on the server of the Medical University of Lublin available at: https://www.umlub.pl/uczelnia/struktura-organizacyjna/szczegoly,317.html. In the internal technical tests of the Risk Calculator using the previously mentioned 50 cases, 36 cases were correctly estimated, which is an accuracy of 72%.
Discussion
As the main objective of the study, an artificial neural network was developed, which, based only on simple information collected in the form of a questionnaire, is able to determine the result of a test to detect SARS-CoV-2 after ACII with useful accuracy. The creation of this network has made it possible to develop a tool that allows the initial identification of persons with a high risk of SARS-CoV-2 infection by healthcare workers, as well as disease-control and epidemiological institutions, without the need to use limited resources such as specific tests, and even before the infection itself develops. It also enables self-examination and, if a high risk of infection is identified, self-isolation until a test can be performed to detect infection. The model has been made public for general use in the form of a SARS-CoV-2 infection Risk Calculator on the server of the Medical University of Lublin, at: https://www.umlub.pl/uczelnia/struktura-organizacyjna/szczegoly,317.html.
The testing group’s prediction accuracy of 78.7% demonstrates the network’s high ability to generalise the knowledge accumulated in the learning group to new cases. Among the exponents of the quality of prediction, a satisfactory level of 86.2% was reached in the measure of sensitivity by the model, which ensures the detection of the vast majority of high-risk cases of infection, thereby reducing the risk of spreading the pathogen. The AUROC of 0.759 in this group is reduced by the lower level of specificity of the model, which reached 68.2% in the test group (80.6% in COVID-TOTAL), although according to the principles of the study derived from the available literature [15] and opinion of the expert, this measure has a much lower level of significance in assessing the quality of model of this type of problem, since false positives have much smaller epidemiological consequences than false negatives.
The selection of questions for the questionnaire was based on reports published during the pandemic period, government recommendations and restrictions, and expert opinion regarding potential risk and protective factors, such as wearing protective masks, washing hands, disinfecting everyday objects, comorbidities, or medications taken [16]. The set of variables was also expanded to include a range of lifestyle factors such as work environment, sleep quality, and service use, in order to maximise the number of possible factors that could affect transmission and disease severity. In the course of developing the network as described in the Material and methods section, the number of these variables was successively reduced to cut back the number of input neurons of the network for the sake of generalisation quality and convenience of the Risk Calculator usage. The values of weight parameters of the network were not included in this article, due to the fact that they should not be interpreted as a measure of the influence of a given factor on the risk of infection, since the model presented is a behavioural model, and therefore represents the behaviour of the modelled system, rather than the true internal interdependencies of its components.
A review of the available literature revealed two dominant approaches of researchers in the search for diagnostic methods that can determine the risk of infection or severity of already developed infection, which do not require an antigen test or PCR, and utilise artificial intelligence methods. The first one involves the use of diagnostic imaging, X-ray, and CT of the lungs, to teach the network what the characteristic features of COVID-19 pneumonia are, so that automatic diagnosis and differentiation of the aetiology of pneumonia are possible [17–19]. The second approach involves analysing total blood counts and biochemical markers to determine factors which would be – analogous to the case of diagnostic imaging – as specific for SARS-CoV-2 infection as possible [20–22]. A major difference in the case of our model, working in its favour, was the development of a tool that uses only questions that can be asked of the patient during the collection of standard medical history, even remotely, without performing medical procedures such as drawing blood for testing or performing imaging diagnostics. This minimizes contact between the potentially ill person and medical personnel and reduces the chance of transmission, which helps reduce costs to the healthcare system and its occupancy by allowing patients to self-examine and self-isolate. In addition, most studies assume the creation of a model assessing an already developed infection, while our model estimates the risk of its development prospectively. This makes it possible to identify those at high risk of COVID-19 infection and the possibility of subjecting them to isolation even before the infection develops At the same time it allows for identification of those at low risk of infection after contact with a sick person, which makes it possible to avoid unnecessary isolation, which is particularly important in context of unnecessary quarantines imposed on key workers after low risk contact with COVID-19 cases, e.g. by hospital personnel. The effectiveness of this model also opens new horizons in fighting other potential new infectious diseases which are, as mentioned before, known to occur periodically, in the case of epidemics every few years, and in the case of global pandemics every few decades [9].
A limitation of the study was the large number of variables included in the questionnaire used for data extraction, which in theory provided the opportunity for extensive analysis of the relevance of a given factor, but in practice discouraged potential respondents from participating in the survey. This resulted in an extended data collection period, i.e. between June 2020 and August 2022, due to which, combined with the dynamically changing epidemiological situation and related changing recommendations, the tool may require updates in the future, which is the purpose of the already planned followup study. Also, the number of cases used to teach the network may have been a limitation; publicly available networks for identifying images such as ResNet-50 [23] and GoogLeNet [24] were trained on tens of thousands of cases, significantly increasing their predictive capabilities [25]. Researchers involved in the future development of artificial neural networks should take note of the software environment they will be using. The Statistica software allows for convenient aggregation and data management, but tools developed using the Python programming language, e.g. TensorFlow [26], offer implementation of techniques such as hardware acceleration, significantly speeding up the process of network construction, but require the researcher to be much more competent in programming, which may require the involvement of interprofessional teams, including experts in biomedical engineering for further cooperation.
This study was carried out by a group of medical students under the supervision of experts in the field of epidemiology and statistical analysis. It was carried out as part of a scientific and educational project organised by the Polish Ministry of Science and Education, aimed at supporting students’ research and innovative projects, the transfer of knowledge acquired in research to the economic sphere, and the acquisition of soft skills by students.
In conclusions, a tool capable of assessing the risk of SARS-CoV-2 infection in a person after contact with a person infected with COVID-19 with 84.5% precision has been created. It is, to our knowledge, the only publicly available tool to estimate the risk of infection, allowing, if a high risk of infection is estimated, to implement preventive measures such as self-isolation. Due to the non-ideal sensitivity level of the model, we recommend performing a diagnostic test if a low risk of infection is estimated. Its creation will also prove to be an important precedent in the fight against potential outbreaks of new pathogens through the use of analogous methods.